I’m in the process of setting up a FreeBSD jail in which to run a local mail-server, mostly for work. As the main purpose will be simply archiving mails for posterity (does anyone ever actually delete emails these days?), I thought I’d investigate which of ZFS’s compression algorithms offers the best trade-off between sped and compression-ratio achieved.
The Dataset
The email corpus comprises 273,273 files totalling 2.14GB; the average size is 8KB and the vast majority are 2.5KB.
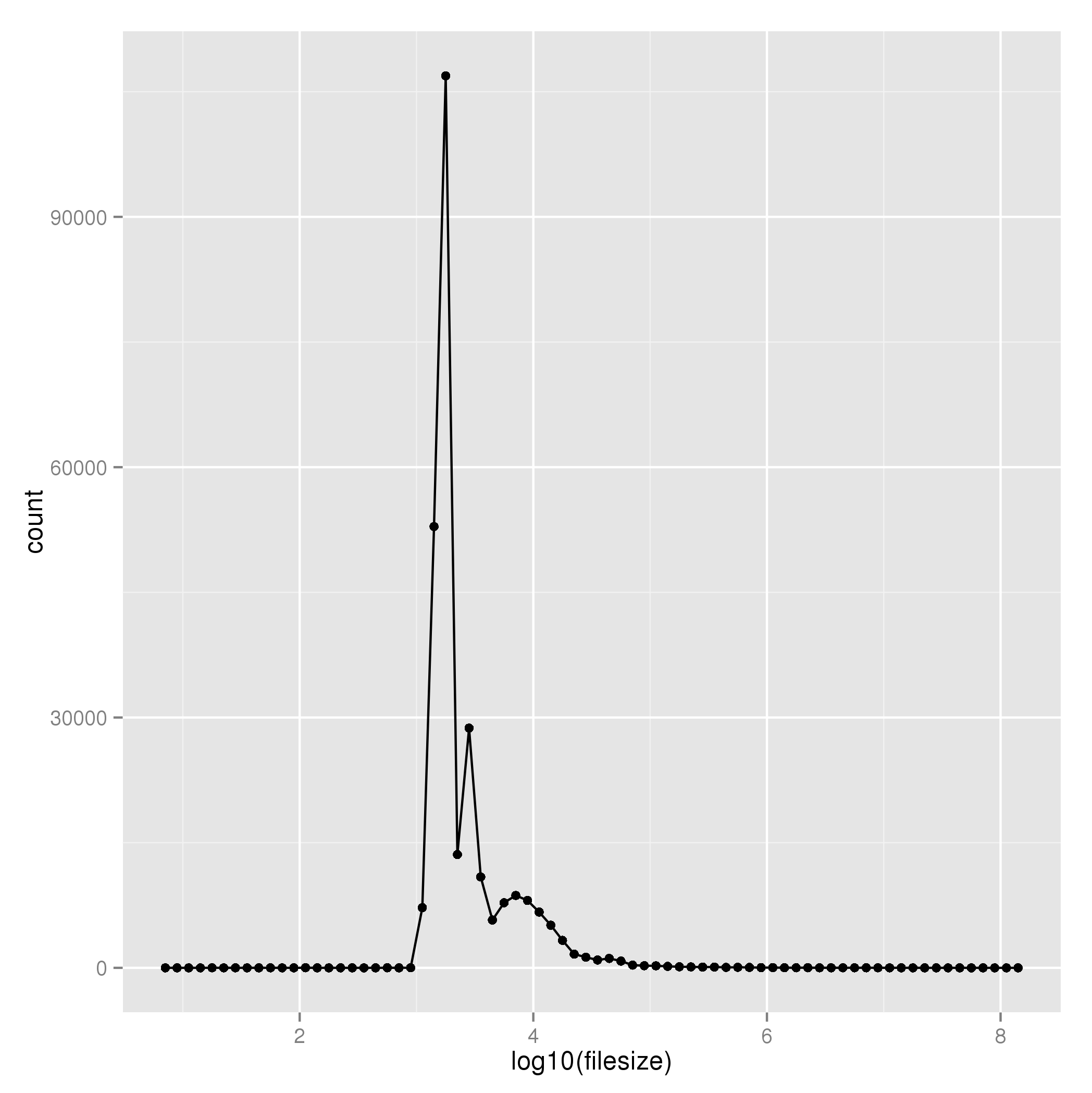
The Test
The test is simple: the algorithms consist of 9 levels of gzip compression plus a new method, lzjb which is noted for being fast, if not compressing particularly effectively.
A test run consists of two parts: copying the entire email corpus from the regular directory to a new temporary zfs filesystem, first using a single thread and then using two parallel threads – using the old but efficient find . | cpio -pdv construct allows the file-list to be sorted in ascending and descending order and two shell-jobs spawned to run simultaneously in the background. Because the server was running with a live load at the time, a test was run 5 times for each algorithm.
The test script is as follows:
#!/bin/zsh
cd /data/mail || exit -1
zfs destroy data/temp
foreach i ( gzip-1 gzip-2 gzip-3 gzip-4 gzip-5 gzip-6 \
gzip-7 gzip-8 gzip-9 lzjb ) {
echo “DEBUG: Doing $i”
zfs create -ocompression=$i data/temp
echo “DEBUG: Partition created”
t1=$(date +%s)
find . | cpio -pdu /data/temp 2>/dev/null
t2=$(date +%s)
size=$(zfs list -H data/temp)
compr=$(zfs get -H compressratio data/temp)
echo “$i,$size,$compr,$t1,$t2,”
zfs destroy data/temp
sync
sleep 5
sync
echo “DEBUG: Doing $i – parallel”
zfs create -ocompression=$i data/temp
echo “DEBUG: Partition created”
t1=$(date +%s)
find . | sort | cpio -pdu /data/temp 2>/dev/null &
find . | sort -r | cpio -pdu /data/temp 2>/dev/null &
wait
t2=$(date +%s)
size=$(zfs list -H data/temp)
compr=$(zfs get -H compressratio data/temp)
echo “$i,$size,$compr,$t1,$t2,parallel”
zfs destroy data/temp
}
zfs destroy data/temp
echo “DONE”
Results
The script’s output was massaged with a bit of commandline awk and sed and vi to make a CSV file, which was loaded into R.
The runs were aggregated according to algorithm and whether one or two threads were used, by taking the mean removing 10% outliers.
Since it is desirable for an algorithm both to compress well and not take much time to do it, it was decided to define efficiency = compressratio / timetaken.
The aggregated data looks like this:
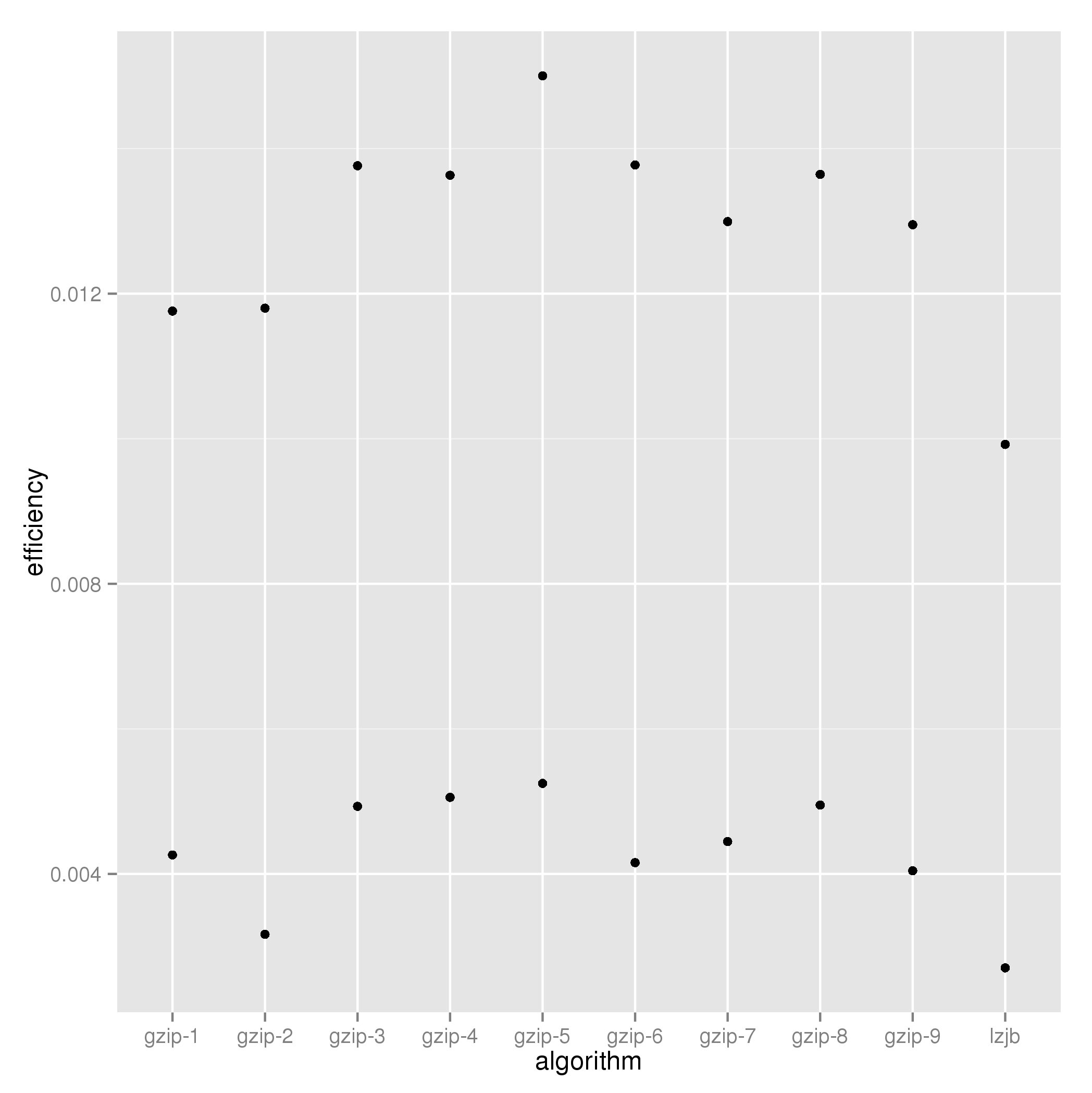
algorithm nowriters eff timetaken compressratio
1 gzip-1 1 0.011760128 260.0 2.583
2 gzip-2 1 0.011800408 286.2 2.613
3 gzip-3 1 0.013763665 196.4 2.639
4 gzip-4 1 0.013632926 205.0 2.697
5 gzip-5 1 0.015003015 183.4 2.723
6 gzip-6 1 0.013774746 201.4 2.743
7 gzip-7 1 0.012994211 214.6 2.747
8 gzip-8 1 0.013645055 203.6 2.757
9 gzip-9 1 0.012950727 215.2 2.755
10 lzjb 1 0.009921776 181.6 1.669
11 gzip-1 2 0.004261760 677.6 2.577
12 gzip-2 2 0.003167507 1178.4 2.601
13 gzip-3 2 0.004932052 539.4 2.625
14 gzip-4 2 0.005056057 539.6 2.691
15 gzip-5 2 0.005248420 528.6 2.721
16 gzip-6 2 0.004156005 709.8 2.731
17 gzip-7 2 0.004446555 644.8 2.739
18 gzip-8 2 0.004949638 566.0 2.741
19 gzip-9 2 0.004044351 727.6 2.747
20 lzjb 2 0.002705393 900.8 1.657
A plot of efficiency against algorithm shows two clear bands, for the number of jobs writing simultaneously.
Analysis
In both cases, the lzjb algorithm’s apparent speed is more than compensated for by its limited compression ratio achievements.
In both cases, although its lead margin is much reduced by running two writers in parallel, the gzip-5 algorithm is most effiicient.
Of course, your mileage may vary; feel free to perform similar tests on your own setup, but I know which method I’ll be using on my new mail server.
Thanks! if you ever retest, it would be great if you could test plzip (as well as lz4).
My findings have been that lz4’s default is the best for speed, & plzip & lz4 at -3 are still quite fast, & beyond that space savings start to hit the law of diminishing returns.
What about LZ4?
Good question. I suspect it hadn’t been invented back when I was testing all this.