Over the past couple of months, I’ve been both learning the R language and boosting my understanding of statistics, the one feeding off the other. To aid the learning process, I set myself a project, to answer the age-old question: which lossy audio format is best for encoding my music collection? Does it matter if I use Ogg (oggenc), MP3 (lame) or AAC (faac), and if so, what bitrate should I use? Is there any significance in the common formats such as mp3 at 128 or 192kbit/s?
First, a disclaimer: when it comes to assessing the accuracy of encoding formats, there are three ways to do it: you can listen to the differences, you can see them, or you can count them. This experiment aims to be objective through a brute-force test, given the constraints of my CD library. Therefore headphones, ears , speakers and fallible human senses do not feature in this – we’re into counting statistical differences, regardless of the nature of the effect they have on the listening experience. It is assumed that the uncompressed audio waveform as ripped from CD expresses the authoritative intent of its artists and sound engineers – and their equipment is more expensive than mine. For the purposes of this test, what matters is to analyze how closely the results of encoding and decoding compare with the original uncompressed wave.
I chose a simple metric to measure this: the root-mean-square (RMS) difference between corresponding samples as a measure of the distance between the original and processed waves. Small values are better – the processed wave is a more faithful reproduction the closer the RMSD is to zero. The primary aim is to get a feel for how the RMSD varies with bitrate and encoding format.
For a representative sample, I started with the Soundcheck CD – 92 tracks, consisting of a mixture of precisely controlled audio tests and some sound-effects and samples, augmented further with a mixture of a small number of CDs of my own – some rock (Queen, Runrig) and classical (Dvorak, Bach and Beethoven).
On the way, I encountered a few surprises, starting with this:
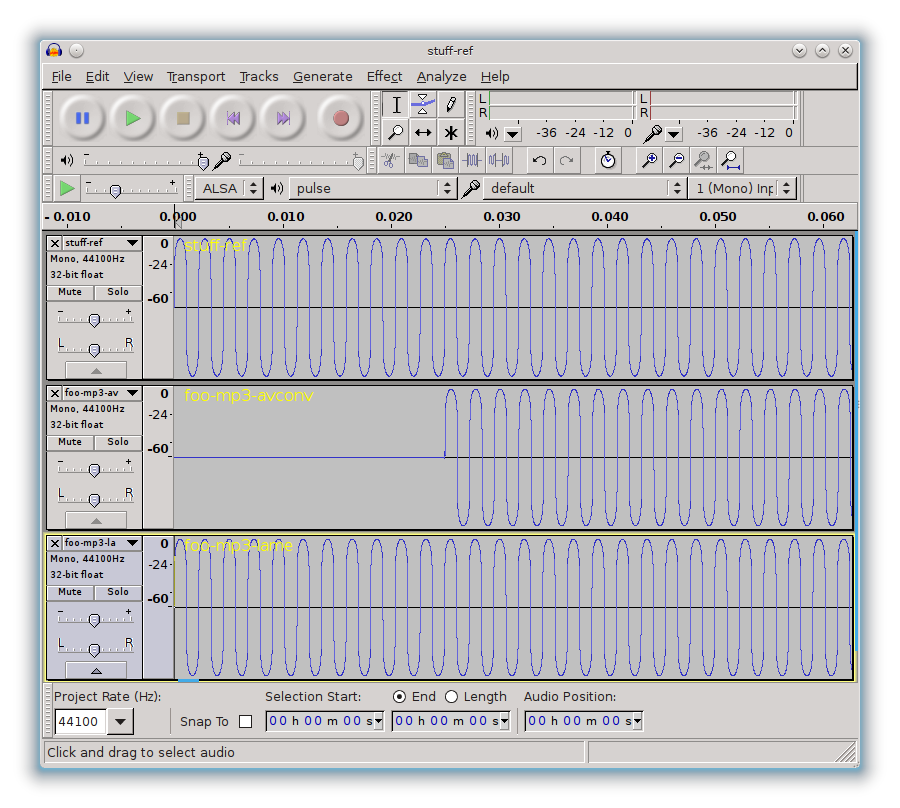
Errors using avconv to decode mp3
Initially I was using Arch Linux, where sox is compiled with the ability to decode mp3 straight to wav. The problem being: it prepends approximately 1300 zero samples at the start of the output (and slightly distorts the start). Using avconv instead had no such problem. I then switched to Ubuntu Linux, where the opposite problem occurs: sox is compiled without support for mp3, and instead it’s avconv that inserts the zero samples as the above screenshot of Audacity shows. Therefore, I settled on using lame both to encode and decode.
One pleasant surprise, however: loading wav files into R just requires two commands:
install.packages("audio")
library("audio")
and then the function load.wave(filename) will load a file straight into a (long) vector, normalized into the range [-1,1]. What could be easier?
At this point, interested readers might wish to see the sources used: R audio encoding comparison. I used a zsh script to iterate over bitrates, varying the commands used for each format; a further script iterates over files in other subdirectories as well. R scripts were used for calculating the RMSD between two wavs and for performing statistical analysis.
To complicate matters further, lame, the mp3 encoder, offers several algorithms to choose between: straightforward variable-bitrate encoding, optionally with a “-h” switch to enable higher quality, optionally with a lower bound “-b”, or alternatively, constant bitrate. Further, faac, the AAC encoder, offers a quality control (“-q”).
The formats and commands used to generate them are as follows:
| AAC-100 | faac -q 100 -b $i -o foo.aac “$src” 2 |
| AAC-80 | faac -q 80 -b $i -o foo.aac “$src” 2 |
| mp3hu | lame –quiet –abr $i -b 100 -h “$src” foo.mp3 |
| mp3h | lame –quiet –abr $i -h “$src” foo.mp3 |
| mp3 | lame –quiet –abr $i “$src” foo.mp3 |
| mp3-cbr | lame –quiet –cbr -b $i “$src” foo.mp3 |
| ogg | oggenc –quiet -b $i “$src” -o foo.ogg |
As a measure of the size of the experiment: 150 tracks were encoded to Ogg, all four variants of MP3 and AAC at bitrates varying from 32 to 320kbit/s in steps of 5kbps.
The distribution of genres reflected in the sample size is as follows:
| Genre | number of tracks |
| Noise (pink noise with variations) | 5 |
| Technical | 63 |
| Instrumental | 20 |
| Vocal | 2 |
| Classical | 39 |
| Rock | 21 |
Final totals: 30450 encode+decode operations taking approximately 40 hours to run.
The Analysis
Reassuringly, a quick regression test shows that the RMSD (“deltas”) column is significantly dependent on both bitrate, mp3 and ogg:
> fit<-lm(deltas ~ bitrate+format, d) > summary(fit)
Call:
lm(formula = deltas ~ bitrate + format, data = d)
Residuals:
Min 1Q Median 3Q Max
-0.06063 -0.02531 -0.00685 0.01225 0.49041
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.348e-02 8.663e-04 73.274 < 2e-16 ***
bitrate -3.048e-04 3.091e-06 -98.601 < 2e-16 ***
formatAAC-80 -9.696e-16 9.674e-04 0.000 1.000000
formatmp3 2.331e-02 9.674e-04 24.091 < 2e-16 ***
formatmp3-cbr 2.325e-02 9.674e-04 24.034 < 2e-16 ***
formatmp3h 2.353e-02 9.674e-04 24.324 < 2e-16 ***
formatmp3hu 2.353e-02 9.674e-04 24.325 < 2e-16 ***
formatogg 3.690e-03 9.676e-04 3.814 0.000137 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.04512 on 30438 degrees of freedom
(4 observations deleted due to missingness)
Multiple R-squared: 0.275, Adjusted R-squared: 0.2748
F-statistic: 1649 on 7 and 30438 DF, p-value: < 2.2e-16
Note that, for the most part, the low p-values indicate a strong dependence of RMSD (“deltas”) on bitrate and format; we’ll address the AAC rows in a minute. Comparing correlations (with the cor function) shows:
Contributing factors - deltas:
trackno bitrate format genre complexity
0.123461675 0.481264066 0.078584139 0.056769403 0.007699271
The genre and complexity columns are added by hand by lookup against a hand-coded CSV spreadsheet; the genre is useful but complexity was mostly a guess and will not be pursued further.
In the subsequent graphs, the lines are coloured by format as follows:
- green – ogg
- black – AAC
- red – mp3 (ordinary VBR)
- purple – mp3 (VBR with -h)
- orange – mp3 (VBR with -b 100 lower bound)
- blue – mp3 (CBR)
A complete overview:
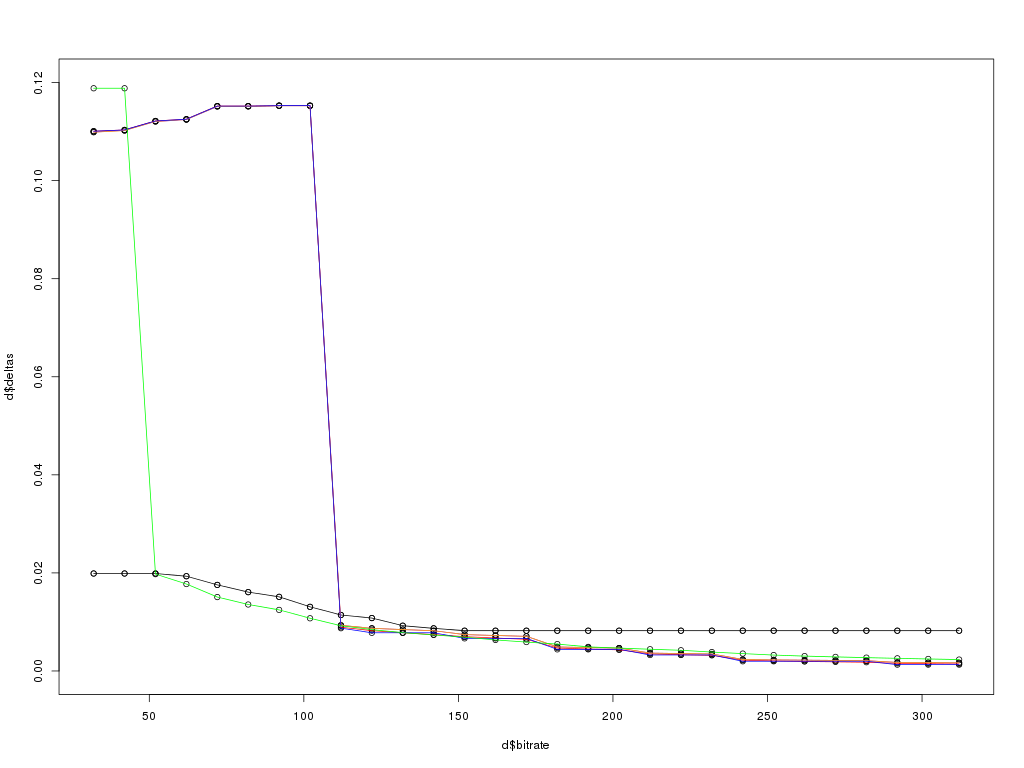
Encoding errors, overview
Already we can see two surprises:
- some drastic behaviour at low bitrates: up to 50kbit/s, ogg is hopelessly inaccurate; mp3 persists, actually getting worse, until 100kbit/s.
- There is no purple line; the mp3 encoded with lame‘s -h switch is indistinguishable from vanilla mp3.
- There is only one black line, showing the faac AAC encoder ignores the quality setting (80 or 100% – both are superimposed) and appears to constrains the bitrate to a maximum of 150kbps, outputting identical files regardless of the rate requested above that limit.
On the strength of these observations, further analysis concentrates on higher bitrates above 100kbit/s only, the AAC format is dropped entirely and mp3h is ignored.
This changes the statistics significantly. Aggregating the average RMSD (deltas) by genre for all bitrates and formats, with the entire data-set we see:
Aggregates by genre:
genre deltas
1 0-Noise 0.016521056
2 1-Technical 0.012121707
3 2-Instrumental 0.009528249
4 3-Voice 0.009226851
5 4-Classical 0.011838209
6 5-Rock 0.017322585
While when only considering higher bitrates, the same average deltas are now drastically reduced:
Aggregates by genre - high-bitrate:
genre deltas
1 0-Noise 0.006603641
2 1-Technical 0.003645403
3 2-Instrumental 0.003438490
4 3-Voice 0.005419467
5 4-Classical 0.004444285
6 5-Rock 0.007251133
The high-bitrate end of the graph, coupled with the blend of genres, represents the likeliest real-world uses. Zooming in:

Encoding errors, high bitrate only
Reassuringly, for each format the general trend is definitely downwards. However, a few further observations await:
- Ogg is the smoothest curve, but above about 180kbit/s, is left behind by all the variants of mp3.
- The orange line (mp3, VBR with a lower bound of 100kbit/s) was introduced because of the performance at the low-bitrate end of the graph. Unexpectedly, this consistently performs worse than straightforward mp3 with VBR including lower bitrates.
- All the mp3 lines exhibit steps where a few points have a shallow gradient followed by a larger jump to the next. We would need to examine the mp3 algorithm itself to try to understand why.
Deductions
Two frequently encountered bitrates in the wild are 128 and 192kbit/s. Comparing the mean RMSDs at these rates and for all bitrates above 100kbit/s, we see:
format deltas(128) deltas(192) deltas(hbr) 1 AAC-100 0.009242665 0.008223191 0.006214152 2 AAC-80 0.009242665 0.008223191 0.006214152 3 mp3 0.007813217 0.004489050 0.003357357 4 mp3-cbr 0.007791626 0.004417602 0.003281961 5 mp3h 0.008454780 0.004778378 0.003643497 6 mp3hu 0.008454780 0.004778408 0.003643697 7 ogg 0.007822895 0.004919718 0.003648990
And the conclusion is: at 128 and 192kbps and on average across all higher bitrates, MP3 with constant bitrate encoding is the most accurate.
Should I use it?
The above test of accuracy is only one consideration in one’s choice of data format. Other considerations include the openness of the Ogg format versus patent-encumbrance of mp3 and the degree to which your devices support each format. Note also that the accuracy of mp3-cbr at about 200kbps can be equalled with ogg at about 250kbps if you wish.

Correlations between all combinations of factors
Returning to the disclaimer above: we have reduced the concept of a difference between two waveforms to a single number, the RMSD. To put this number in context, this plot of the waveforms illustrates the scope of errors encountered:
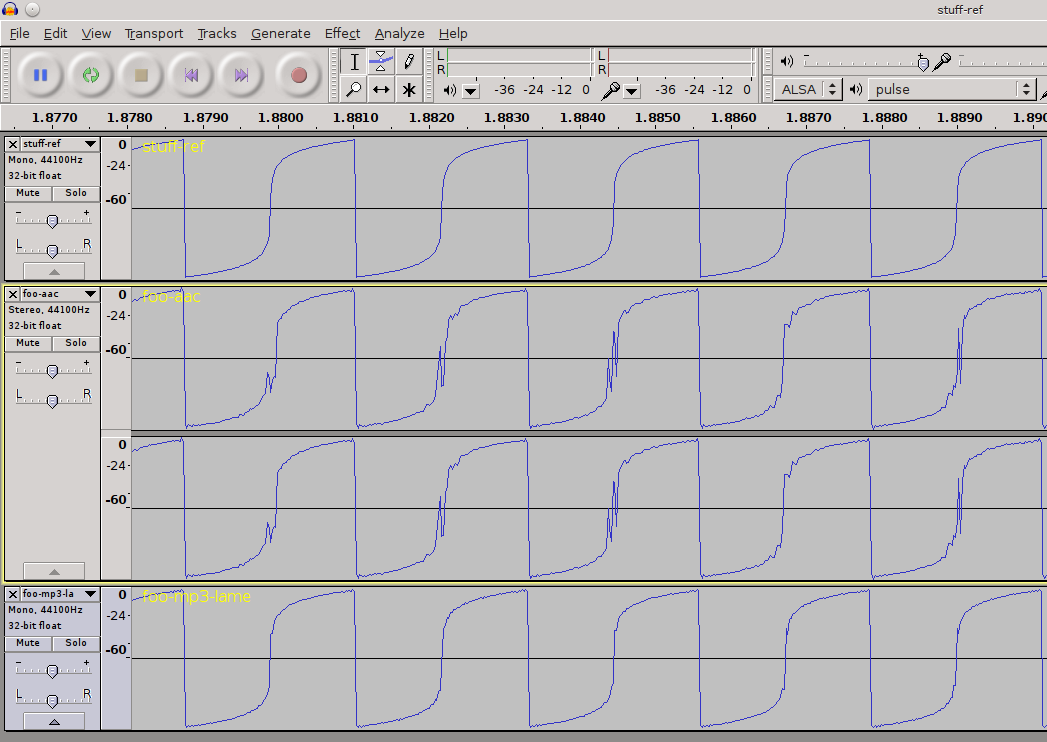
visualizing encoding differences
(Reference wave on top; AAC in the middle showing huge distortion and MP3 on the bottom, showing slight differences.)
This demonstrates why tests based on listening are fallible: the errors will definitely manifest themselves as a different profile in a frequency histogram. When listening to the AAC version, the sound heard is modulated by the product of both residual errors from encoding and the frequency response curve of the headphones or speakers used. Coupled with this, the human ear is not listening for accuracy to a waveform so much as for an enjoyable experience overall – so some kinds of errors might be regarded as pleasurable, mistakenly.
There are be other metrics than RMSD by which the string-distance between source and processed waveforms can be measured. Changing the measuring algorithm is left as an exercise for the reader.
Feel free to download the full results for yourself – beware, the CSV spreadsheet is over 30k rows long.